如何创建最优的线程池
目录
你好,我是范亚敏。
多线程是我们最常用的并行编程工具,也是性能优化在多核处理器时代最常用的手段。而线程池是处理并发请求和任务的常用方法,使用线程池可以减少在创建和销毁线程上所花的时间, 充分利用系统的资源,带给用户更快速的响应。创建一个线程池来并发的任务看起来简单,其实不然,线程池的参数是很有讲究的。初学者常犯的错误就是线程要么忙死,要么闲死。
以 Java 为例,一个标准的线程池创建方法是这样的:
/** Thread Pool Executor */ public ThreadPoolExecutor( int corePoolSize, // 核心线程数 int maxPoolSize, // 最大线程数 long keepAliveTime, // 存活时间,超过 corePoolSize 的空闲线程在此时间之后会被回收 TimeUnit unit, // 存活时间单位 BlockingQueue<Runnable> workQueue// 阻塞的任务队列 RejectedExecutionHandler handler // 当队列已满,线程数已达 maxPoolSize 时的策略 ) {...}
虽然 JDK 提供了一些默认实现,比如这三个:
- static ExecutorService newCachedThreadPool()
- static ExecutorService newFixedThreadPool(int nThreads)
- static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
但是这些线程池并不能满足各种各样的业务场景,在 Java 代码我们一般要求用 ThreadPoolExecutor 来创建线程池,为 ThreadPoolExecutor 设置最优的线程池参数,以满足应用的性能需求。
但是什么样的参数才是合理的,最优的? 这是最让初学者头疼的,没有标准答案,但是有最佳实践。
接下来让我们来仔细分析探讨一下我们在实践中总结出来的先度量再优化的方法。
解决问题:先度量再优化的方法
通常的做法是这样的:
1. 根据经验和通用公式按需求设置相对合理的参数
拿线程池来说, 我们需要考虑线程数设置多少才合适, 这个取决于服务器的 CPU 资源,以及任务的类型和资源消耗情况。
如果任务是读写数据库, 那么它取决于数据库连接池的连接数目, 以及数据库的负载和性能, 而如果任务是通过网络访问第三方服务,那么它取决于网络负载大小,以及第三方服务的负载和性能。
通常来说,CPU 密集型的任务占用 CPU 时间较长,线程数可以设置的小一点, I/O 密集型的任务占用 CPU 时间较短,线程数可以设的大一点。
我们的目的是充分利用给到我们的 CPU 资源,如果线程的任务有很多等待时间,比如等待磁盘和网络 I/O,那么就把线程数设多一点,如果任务本身非常耗费 CPU 的计算资源,CPU 处理时间较长,那么就把线程数设得小一点。
根据这个公式:
线程数 = CPU 核数 * 希望的 CPU 使用率 * (1 + 等待时间 / 处理时间)
假设我们的服务器为 4 核 CPU,我们要创建一个线程池来发送度量数据指标到远端的 Kafka 上,网络延迟约为 50ms,数据解析编码压缩时间大约 5ms,CPU 占用率希望在 10% 之内。根据计算结果,得出我们需要 4.4, 约 5 个线程
4 * 0.1 * (1 + 50 / 5) = 4.4
于是, 我们设置了这些参数,你可以截个图之后再仔细看一下

2. 根据度量指标进行调整
为了进行充分的度量,我们必需对线程池的各种指标进行记录和展示。
我们先来简单了解一些度量术语:
度量注册表 MetricRegistry
它是各种度量数据的容器,类似于 windows 的系统注册表,各项度量数据都可以在其中进行注册。
度量类型 Metrics Type

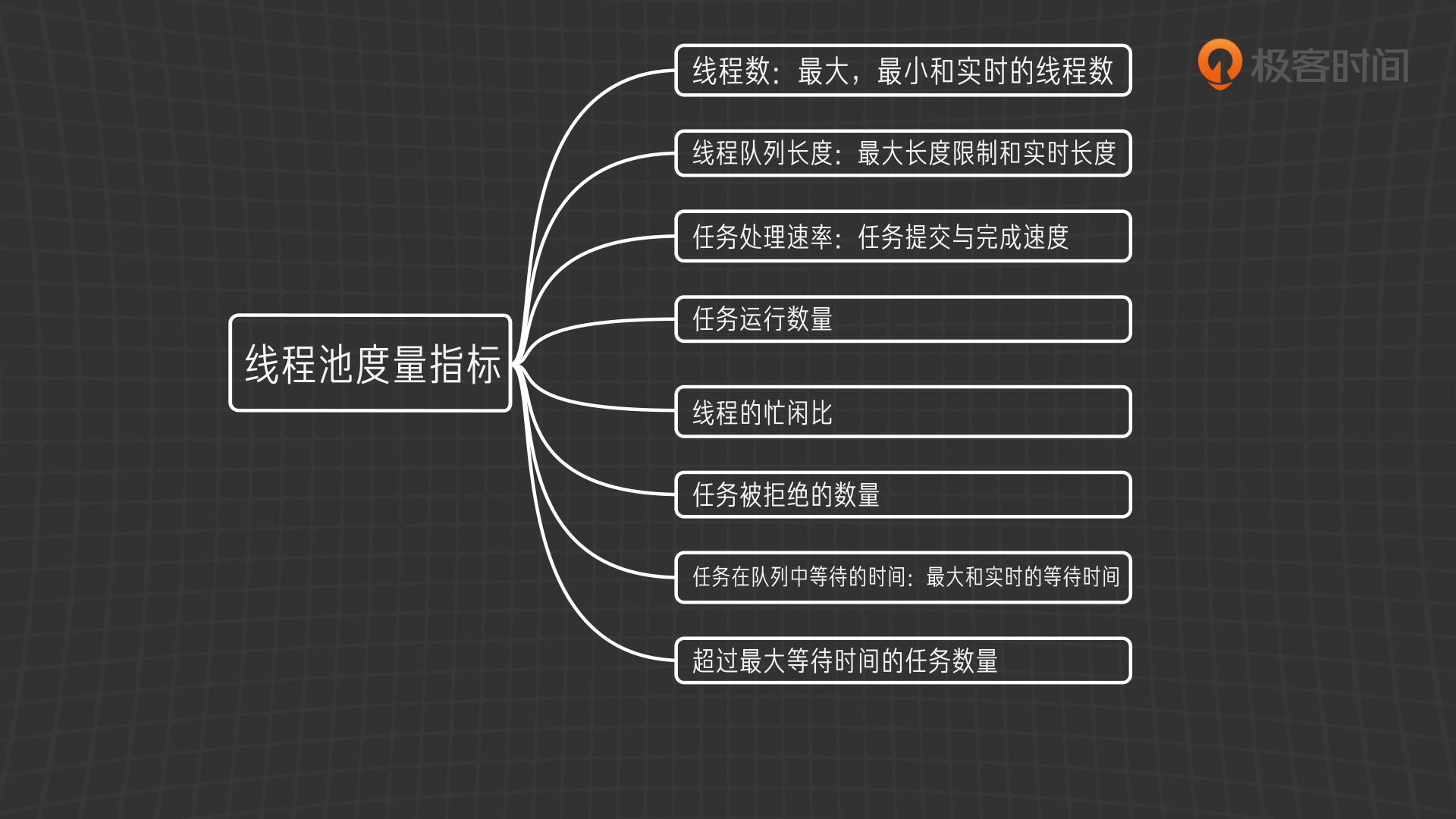
线程相关度量指标
根据以上的度量类型,以及线程池的特点,我们可以想到这些度量指标:

这些度量指标如此重要,在于只有了解了它们,我们才能知道线程池的工作状况,才能进行有的放矢的调优,下面让我们用一个实例来具体说明一下度量驱动调优的方法。
线程池度量实例
这是一个线程池度量调优的实例,主要有三个步骤:
- 创建线程池并注册各项度量指标
- 运行线程池并收集度量指标
- 观察度量指标并相应地调整参数
无度量,不调优, 没有调查取证,就无法做好调优。我们可以应用 dropwizard 的 metrics 库中的 https://metrics.dropwizard.io/ 类库 InstrumentedExecutorService 来帮助我们进行上述指标的统计, 它通过装饰器模式对原来的 Executor Service 进行包装,记录了 submited, running, completed, idle , duration 这些指标,我们可以另外再记录一些指标,来反映线程池的工作情况,以及线程池中运行的任务的执行情况。
部分代码:
先定义一个线程池参数对象
package com.github.walterfan.helloconcurrency; import com.codahale.metrics.Gauge; import com.codahale.metrics.MetricRegistry; import lombok.Builder; import lombok.Getter; import lombok.Setter; import java.time.Duration; /** * @Author: Walter Fan * 这是一个数据传输对象,封装了线程池的关键参数 * * 它也应用了 lombok 的 @Getter, @Setter, @Builder 注解 * 来自动生成 setter, getter 和 build 方法 * **/ @Getter @Setter @Builder public class ThreadPoolParam { private int minPoolSize; private int maxPoolSize; private Duration keepAliveTime; private int queueSize; private String threadPrefix; private boolean daemon; private MetricRegistry metricRegistry; }
再写一个创建线程池的工具类
ThreadPoolUtil.java package com.github.walterfan.helloconcurrency; import com.codahale.metrics.Counter; import com.codahale.metrics.Gauge; import com.codahale.metrics.InstrumentedExecutorService; import com.codahale.metrics.Meter; import com.codahale.metrics.MetricRegistry; import com.google.common.util.concurrent.ThreadFactoryBuilder; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.ExecutorService; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.RejectedExecutionHandler; import java.util.concurrent.ThreadFactory; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; import java.util.function.Supplier; import static com.codahale.metrics.MetricRegistry.name; /** * @Author: Walter Fan **/ @Slf4j public class ThreadPoolUtil { /* 和系统内置的 ThreadPoolExecutor.CallerRunsPolicy 差不多, 如果被拒绝,就用提交任务的线程来执行任务. */ public static class DiscardAndLogPolicy implements RejectedExecutionHandler { final MetricRegistry metricRegistry; final Meter rejectedMeter; final Counter rejectedCounter; public DiscardAndLogPolicy(String threadPrefix, MetricRegistry metricRegistry) { this.metricRegistry = metricRegistry; this.rejectedMeter = metricRegistry.meter(threadPrefix + ".rejected-meter"); this.rejectedCounter = metricRegistry.counter(threadPrefix + ".rejected-counter"); } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { rejectedMeter.mark(); rejectedCounter.inc(); if (!e.isShutdown()) { log.warn("reject task and run {} directly", r); r.run(); } } } // 创建线程执行器,注册了几个度量指标 public static ThreadPoolExecutor createThreadExecutor(ThreadPoolParam threadPoolParam) { MetricRegistry metricRegistry = threadPoolParam.getMetricRegistry(); metricRegistry.register(threadPoolParam.getThreadPrefix() + ".min", createIntGauge(() -> threadPoolParam.getMinPoolSize())); metricRegistry.register(threadPoolParam.getThreadPrefix() + ".max", createIntGauge(() -> threadPoolParam.getMaxPoolSize())); metricRegistry.register(threadPoolParam.getThreadPrefix() + ".queue_limitation", createIntGauge(() -> threadPoolParam.getQueueSize())); ThreadPoolExecutor executor = new ThreadPoolExecutor(threadPoolParam.getMinPoolSize(), threadPoolParam.getMaxPoolSize(), threadPoolParam.getKeepAliveTime().toMillis(), TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(threadPoolParam.getQueueSize()), createThreadFactory(threadPoolParam), createRejectedExecutionHandler(threadPoolParam)); metricRegistry.register(threadPoolParam.getThreadPrefix() + ".pool_size", createIntGauge(() -> executor.getPoolSize())); metricRegistry.register(threadPoolParam.getThreadPrefix() + ".queue_size", createIntGauge(() -> executor.getQueue().size())); return executor; } // 创建线程执行服务,用 InstrumentedExecutorService 来包装和度量线程任务 public static ExecutorService createExecutorService(ThreadPoolParam threadPoolParam) { ThreadPoolExecutor executor = createThreadExecutor(threadPoolParam); return new InstrumentedExecutorService(executor, threadPoolParam.getMetricRegistry(), threadPoolParam.getThreadPrefix()); } private static Gauge<Integer> createIntGauge(Supplier<Integer> suppier) { return () -> suppier.get(); } public static ThreadFactory createThreadFactory(ThreadPoolParam threadPoolParam) { return new ThreadFactoryBuilder() .setDaemon(threadPoolParam.isDaemon()) .setNameFormat(threadPoolParam.getThreadPrefix() + "-%d") .build(); } public static RejectedExecutionHandler createRejectedExecutionHandler(ThreadPoolParam threadPoolParam) { return new DiscardAndLogPolicy(threadPoolParam.getThreadPrefix(), threadPoolParam.getMetricRegistry()); } }
注意: 我们在这个线程池中埋设了 12 个度量指标,看你能不能在代码中找出来设置的地方 。
- cards-thread-pool.completed
- cards-thread-pool.max
- cards-thread-pool.queue_limitation
- cards-thread-pool.rejected-meter
- cards-thread-pool.duration
- cards-thread-pool.min
- cards-thread-pool.queue_size
- cards-thread-pool.running
- cards-thread-pool.idle
- cards-thread-pool.pool_size
- cards-thread-pool.rejected-counter
- cards-thread-pool.submitted
- 用线程池执行多副扑克牌的排序任务
以我们最常用的打扑克牌为例,分别用冒泡排序,插入排序和 JDK 自带的 TimSort 来对若干副牌排序,总共创建 20 个任务,都放入线程池中执行,当我们采用不同的线程池参数时,效果大不相同。扑克牌对象类及其排序代码这里从略, 可以参见 GitHub 上的源码.
这段代码让线程池执行了 30 个排序任务,最多排序 1000 副牌(52000 张),10 个任务用冒泡排序,10 个任务用插入排序,10 个任务用 Tim 排序, 总共花了 18 秒多。
我用 CsvReporter 把若干度量指标打印到 Csv 文件中,一共有 12 个 CSV 文件。
- cards-thread-pool.completed.csv
- cards-thread-pool.max.csv
- cards-thread-pool.queue_limitation.csv
- cards-thread-pool.rejected-meter.csv
- cards-thread-pool.duration.csv
- cards-thread-pool.min.csv
- cards-thread-pool.queue_size.csv
- cards-thread-pool.running.csv
- cards-thread-pool.idle.csv
- cards-thread-pool.pool_size.csv
- cards-thread-pool.rejected-counter.csv
- cards-thread-pool.submitted.csv
- 分析度量指标,根据分析结果进行优化
基于这些度量指标,我们可以看到任务特点和线程池的参数是否合理。最直观的是批量任务的执行时间,任务在线程池队列中堆积的个数和时长,线程池中工作线程的变化,线程池由于过载而丢弃的任务,下面让我们来逐个分析这四个关键指标。
线程池中任务的执行时间
从结果来看,三种排序方法的效率差别很大。排两副牌的时候,三种方法差不太多,而排序 1000 副牌(52000 张)的时候, TimSort 花了大约 11 毫秒, InsertSort 花了大约 1 秒 ,而 BubbleSort 花了 14 秒多。
对于任务执行时间,我们可以通过记录的度量指标文件来作一个分析,下面是运行过程中生成的 csv 文件,看起来不太直观,之后我画一个简单的线形图,你就能理解了。
这是一个表示任务所执行时间的统计值 (最大,平均,最小,标准差,p50 到 p999 的分位数值)。
t,count,max,mean,min,stddev,p50,p75,p95,p98,p99,p999,mean_rate,m1_rate,m5_rate,m15_rate,rate_unit,duration_unit 1585473845,0,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,calls/second,milliseconds 1585473846,0,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,calls/second,milliseconds 1585473846,8,63.069663,37.658003,2.579674,25.915099,39.007040,61.809917,63.069663,63.069663,63.069663,63.069663,33.614807,0.000000,0.000000,0.000000,calls/second,milliseconds 1585473846,8,63.069663,37.658003,2.579674,25.915099,39.007040,61.809917,63.069663,63.069663,63.069663,63.069663,23.777415,0.000000,0.000000,0.000000,calls/second,milliseconds 1585473846,8,63.069663,37.658003,2.579674,25.915099,39.007040,61.809917,63.069663,63.069663,63.069663,63.069663,18.448678,0.000000,0.000000,0.000000,calls/second,milliseconds 1585473846,9,384.357751,76.180197,2.579674,111.663094,58.345330,62.339820,384.357751,384.357751,384.357751,384.357751,16.884697,0.000000,0.000000,0.000000,calls/second,milliseconds # 省略余下内容
这个 csv 文件看起来不直观,我们还是用图表来形象地表示:
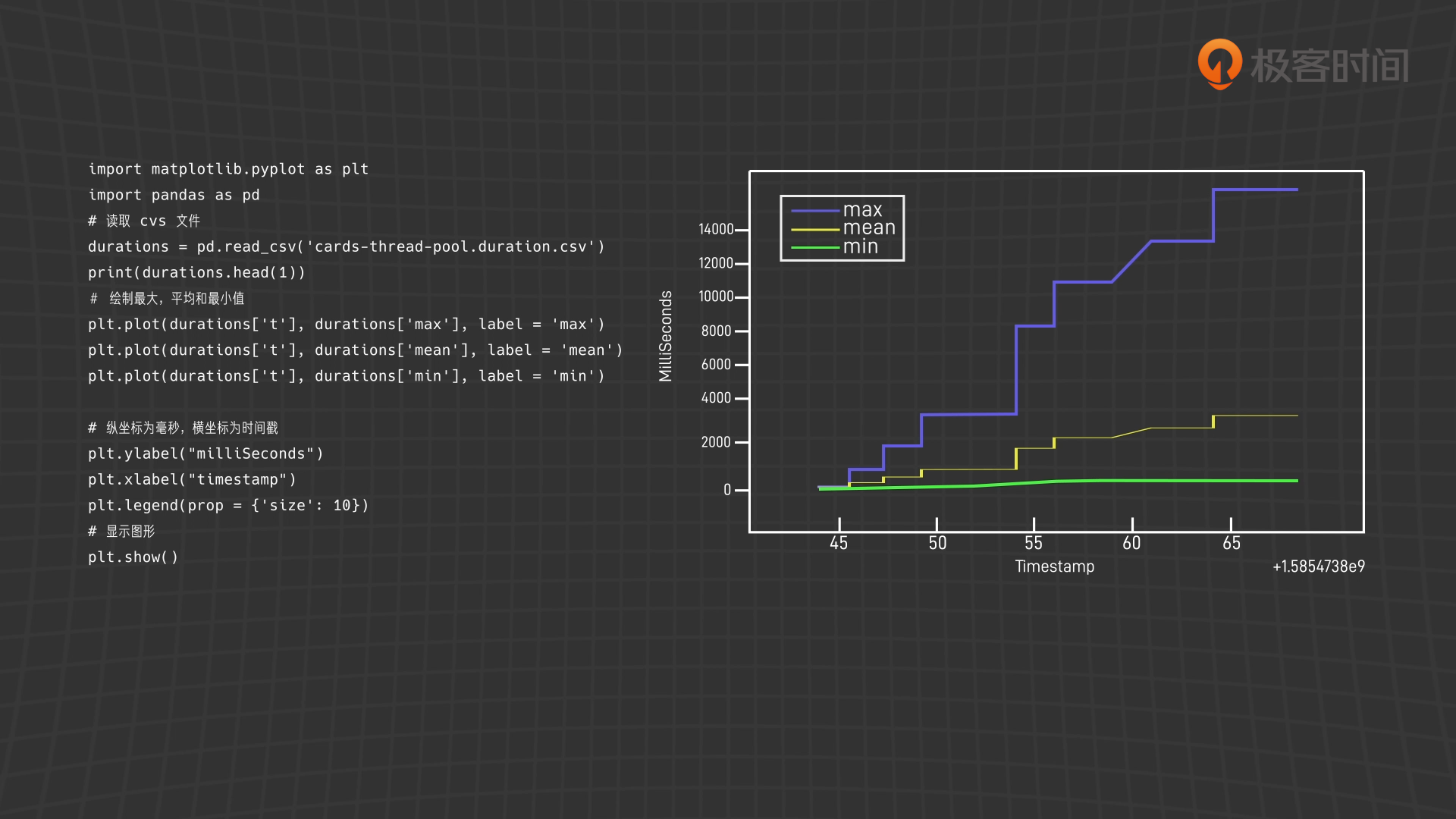
分析任务执行时间的 Python 脚本
import matplotlib.pyplot as plt import pandas as pd # 读取 cvs 文件 durations = pd.read_csv('cards-thread-pool.duration.csv') print(durations.head(1)) # 绘制最大,平均和最小值 plt.plot(durations['t'], durations['max'], label = 'max') plt.plot(durations['t'], durations['mean'], label = 'mean') plt.plot(durations['t'], durations['min'], label = 'min') # 纵坐标为毫秒,横坐标为时间戳 plt.ylabel("milliSeconds") plt.xlabel("timestamp") plt.legend(prop = {'size': 10}) # 显示图形 plt.show()
排序任务时间
线程池中的线程数变化
import matplotlib.pyplot as plt import pandas as pd # 读取 cvs 文件 durations = pd.read_csv('cards-thread-pool.pool_size.csv') print(durations.head(1)) # 绘制图表,横坐标是时间,纵坐标是线程数 plt.plot(durations['t'], durations['value'], label = 'pool size') plt.ylabel("thread count") plt.xlabel("timestamp") plt.legend(prop = {'size': 10}) # 显示图形 plt.show()
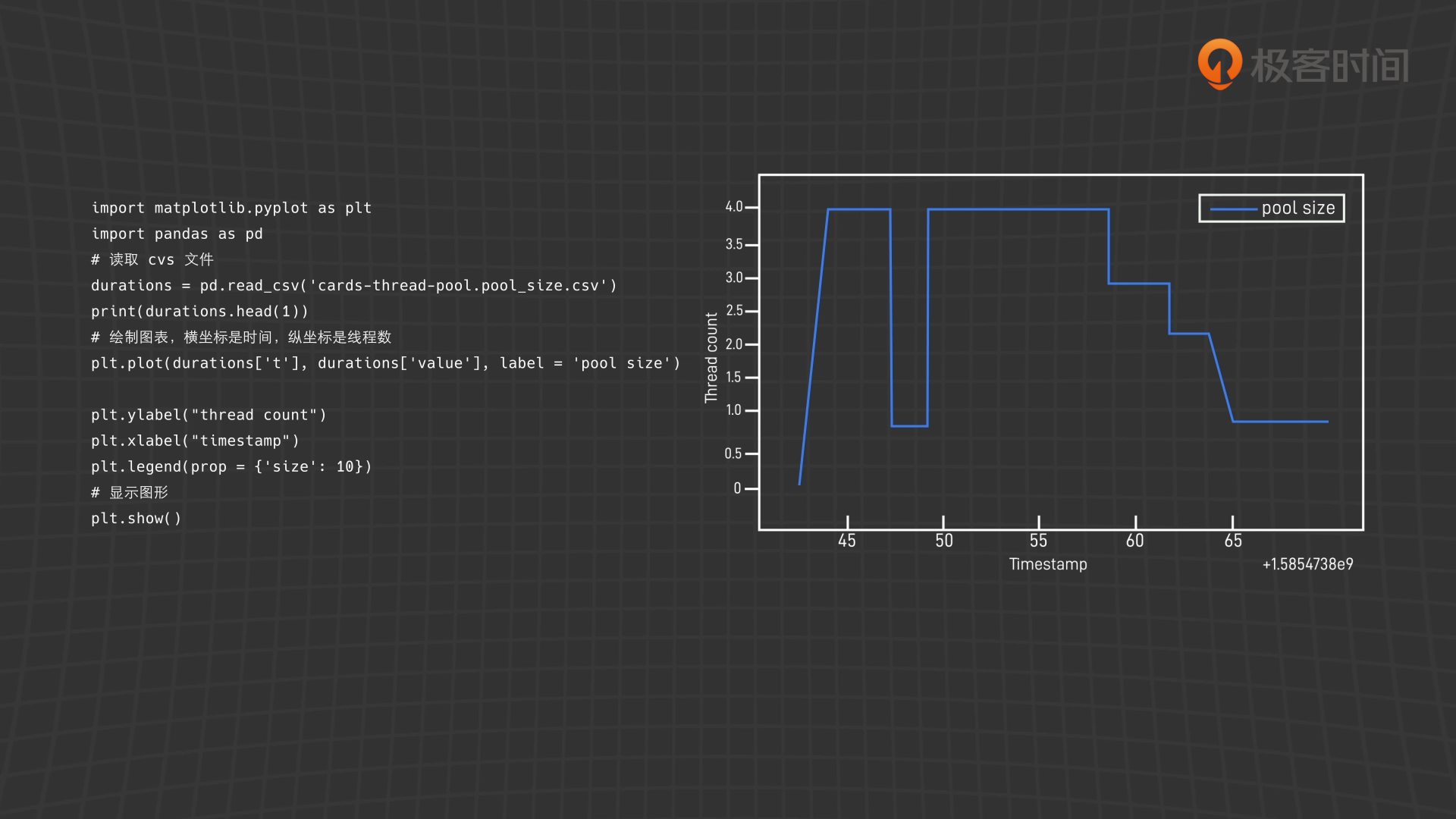
线程池中的线程数
线程池的线程数应该比较平稳,避免频繁的创建和销毁线程,这张图揭示如果系统资源足够的话,corePoolSize, maxPoolSize 和 keepAliveTime 时间可以适当调大。
线程池队列长度
import matplotlib.pyplot as plt import pandas as pd # 读取 cvs 文件 durations = pd.read_csv('cards-thread-pool.queue_size.csv') print(durations.head(1)) # 绘制图表,横坐标是时间,纵坐标是线程队列的堆积的任务数 plt.plot(durations['t'], durations['value'], label = 'queue size') plt.ylabel("queue size") plt.xlabel("timestamp") plt.legend(prop = {'size': 10}) # 显示图形 plt.show()
线程池队列长度
线程池拒绝的任务数
import matplotlib.pyplot as plt import pandas as pd # 读取 cvs 文件 durations = pd.read_csv('cards-thread-pool.rejected-counter.csv') print(durations.head(1)) # 绘制图表,横坐标是时间,纵坐标是线程池由于过载而拒绝的任务数 plt.plot(durations['t'], durations['count'], label = 'rejected count') plt.ylabel("rejected count") plt.xlabel("timestamp") plt.legend(prop = {'size': 10}) # 显示图形 plt.show()
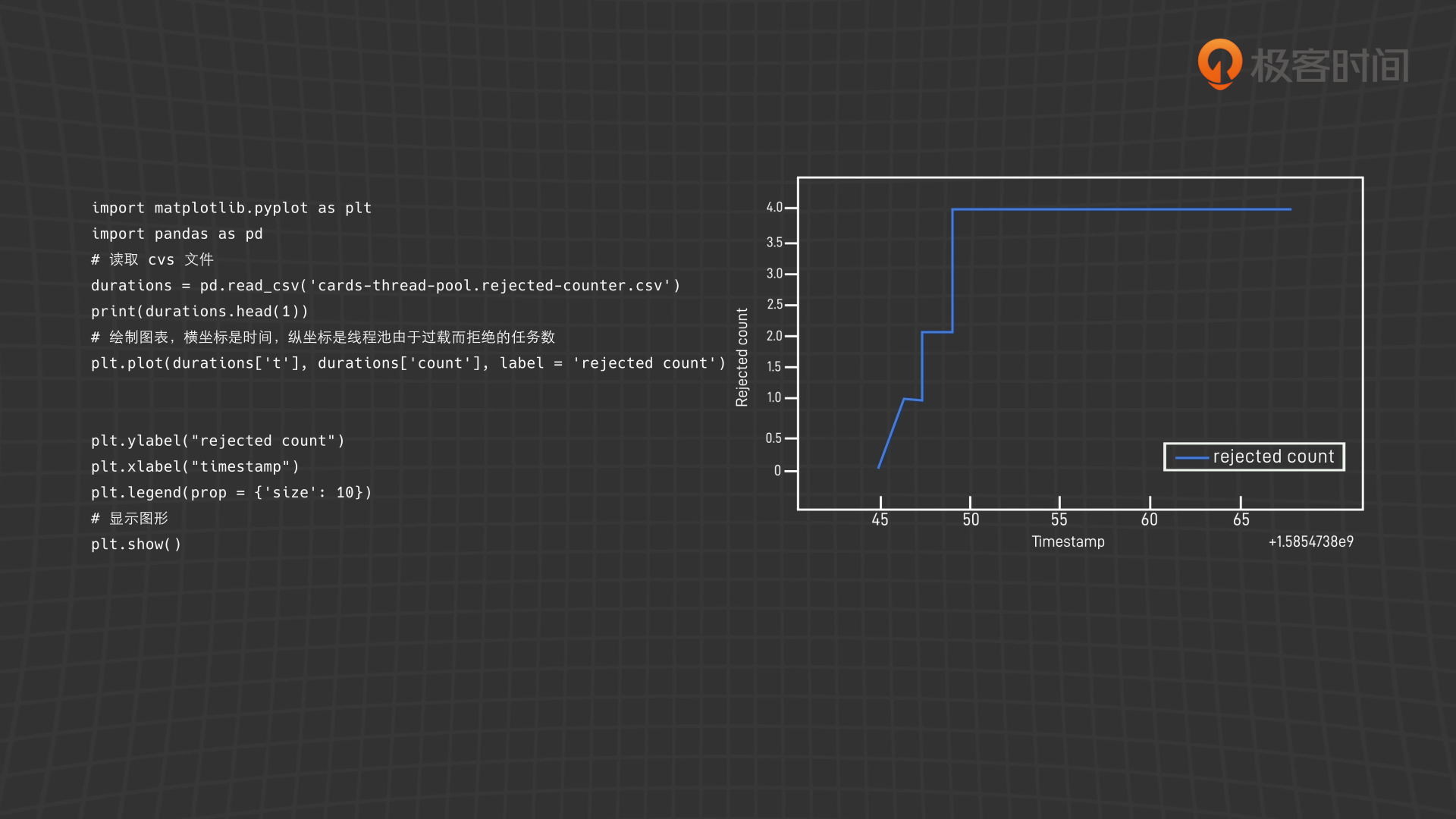
基于被拒绝的任务数来看,显然核心线程数和队列长度应该增大。
总结和延伸思考
度量的关键是要对线程池的工作原理和关键指标了如指掌,优化的依据是对线程池的度量指标进行实时观测,并定时采样记录。我们通过对线程池的进行包装和埋点,得到了关键指标的度量数据
有了这些度量数据,通过数据分析和图表展示,就知道了线程池的工作状况,哪些参数设置得不合理,需要进行调优,有限的系统资源如果满足不了并发任务的需求,则需要增加更多的分布式节点。
我使用了比较简单的 CSV 文件来记录度量指标。在实际工作中,我们经常利用一些时间序列数据库(例如 InfluxDB,Promethues 等)将这些指标保存起来,再利用报表分析工具(Grafana, Graphite 等)对它们进行分析。
好,我是范亚敏,希望我的分享可以帮助到你,也希望你在视频下方的留言区和我讨论。