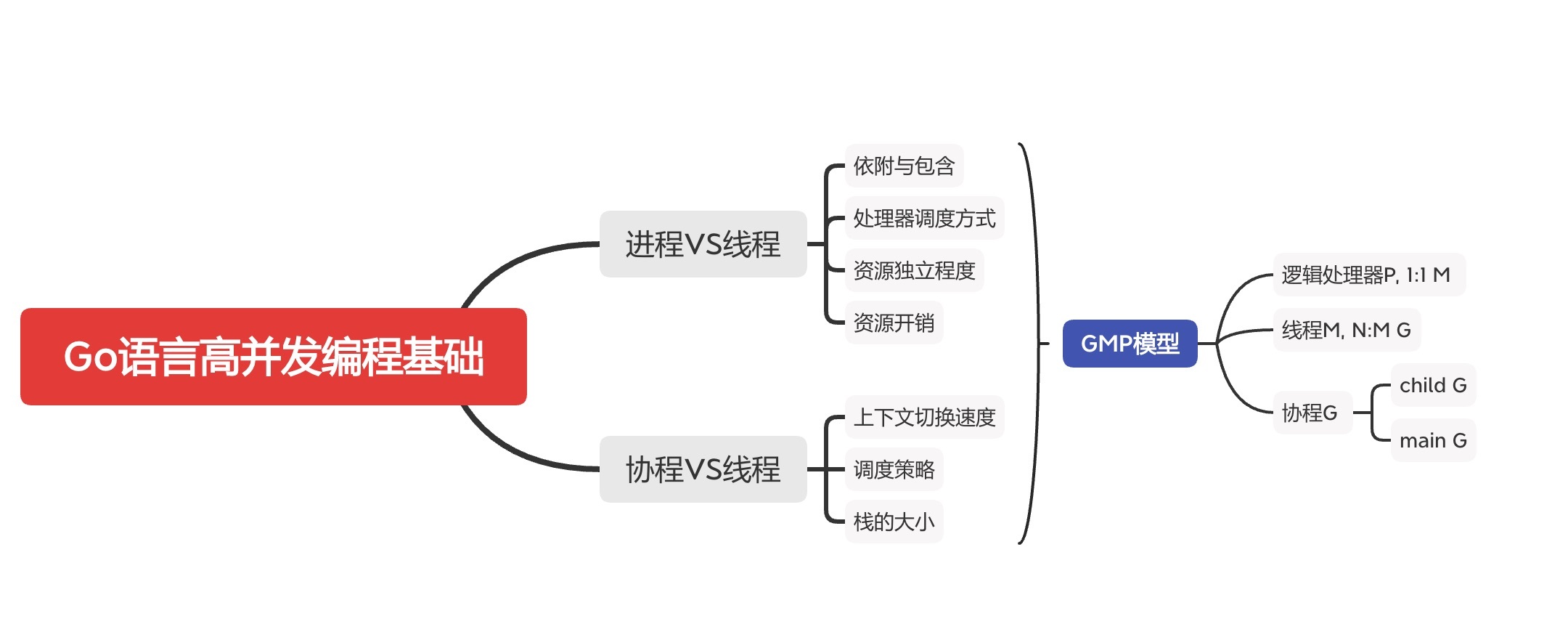
线程与进程 协程的区别到底在哪
你好,我是郑建勋(Jonson)。
大厂在面试过程中考察基础知识时,经常会问到线程与进程、协程的区别,这是很多面试者会困惑的地方。显然,对于 Go 语言基础知识的理解不仅是开发者的基本功,更是进入大公司的入场券。
所以,接下来我会跟你一起梳理 Go 并发编程中几个基础却重要的概念:进程与线程的区别、协程与线程的区别,以及线程、协程与处理器之间关系的 GMP 模型。明白了进程、协程与线程之间基本的区别,你就会明白 Go 的并发与操作系统之间是如何交互的,明白了 GMP 模型调度模型,你就可以从更高的视角理解 Go 的协程如何组织、调度与运行。
进程与线程的区别
在计算机科学中,线程是可以由调度程序(通常是操作系统的一部分)独立管理的最小程序指令集。而进程是程序运行的实例。在大多数情况下,线程是进程的组成部分。所以在一个进程内部,可能会有多个线程同时处理。
比如在浏览器这个进程内部,可以同时访问多个网页,这多个网页就是多个线程,再比如微信这个进程,可以同时接收消息和发消息,收发消息也是多个线程,这都是靠一个进程中包含了多个处理线程实现的。
那为什么程序通常不采取多进程,而是采取多线程的方式设计呢?因为进程有自己独立的内存空间,开启一个新进程的开销要比开启一个新线程大得多,同时也会导致多进程之间的共享通信更加困难。
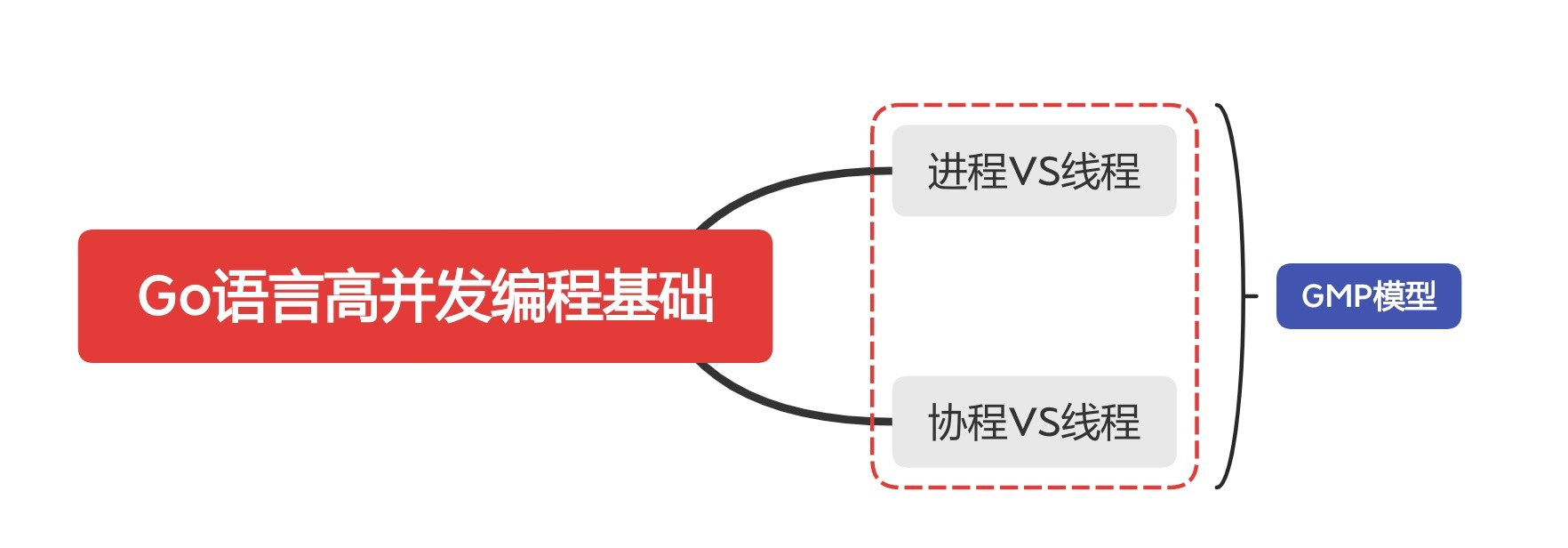
进程中的多个线程并发执行,同时共享进程的内存(例如全局变量)等资源。而进程之间是相对独立的,不同进程之间具有不同的内存地址空间、代表程序运行的机器码、进程状态、操作系统资源描述符等(如下图)。
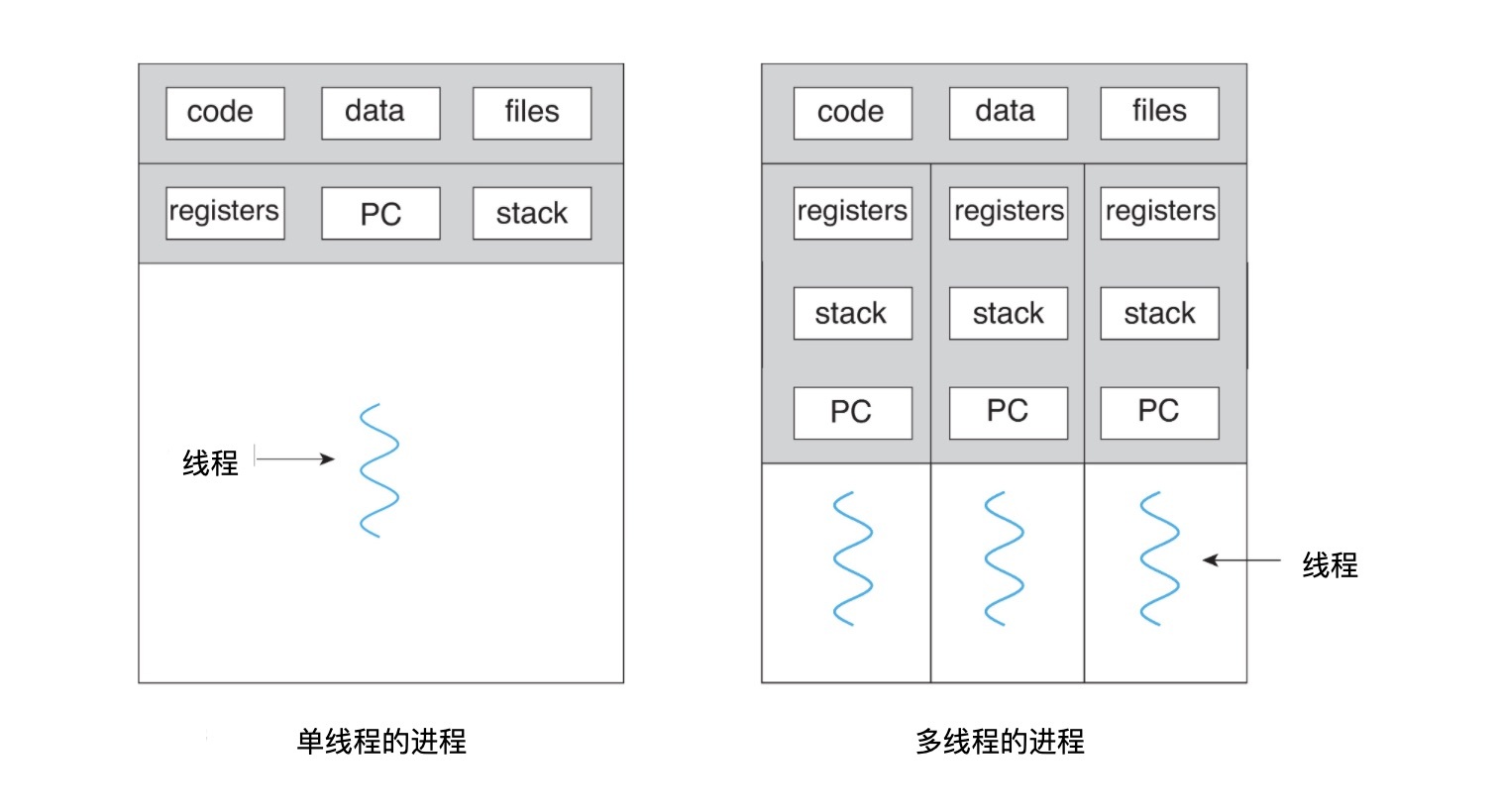
操作系统调度到 CPU 中执行的最小单位是线程。在传统的单核 CPU 上运行的多线程应用程序必须交织线程,交替抢占 CPU 的时间片(如下图所示)。 但是,现代计算机系统普遍拥有多核处理器。在多核 CPU 上,线程可以分布在多个 CPU 核心上,从而实现真正的并行处理。
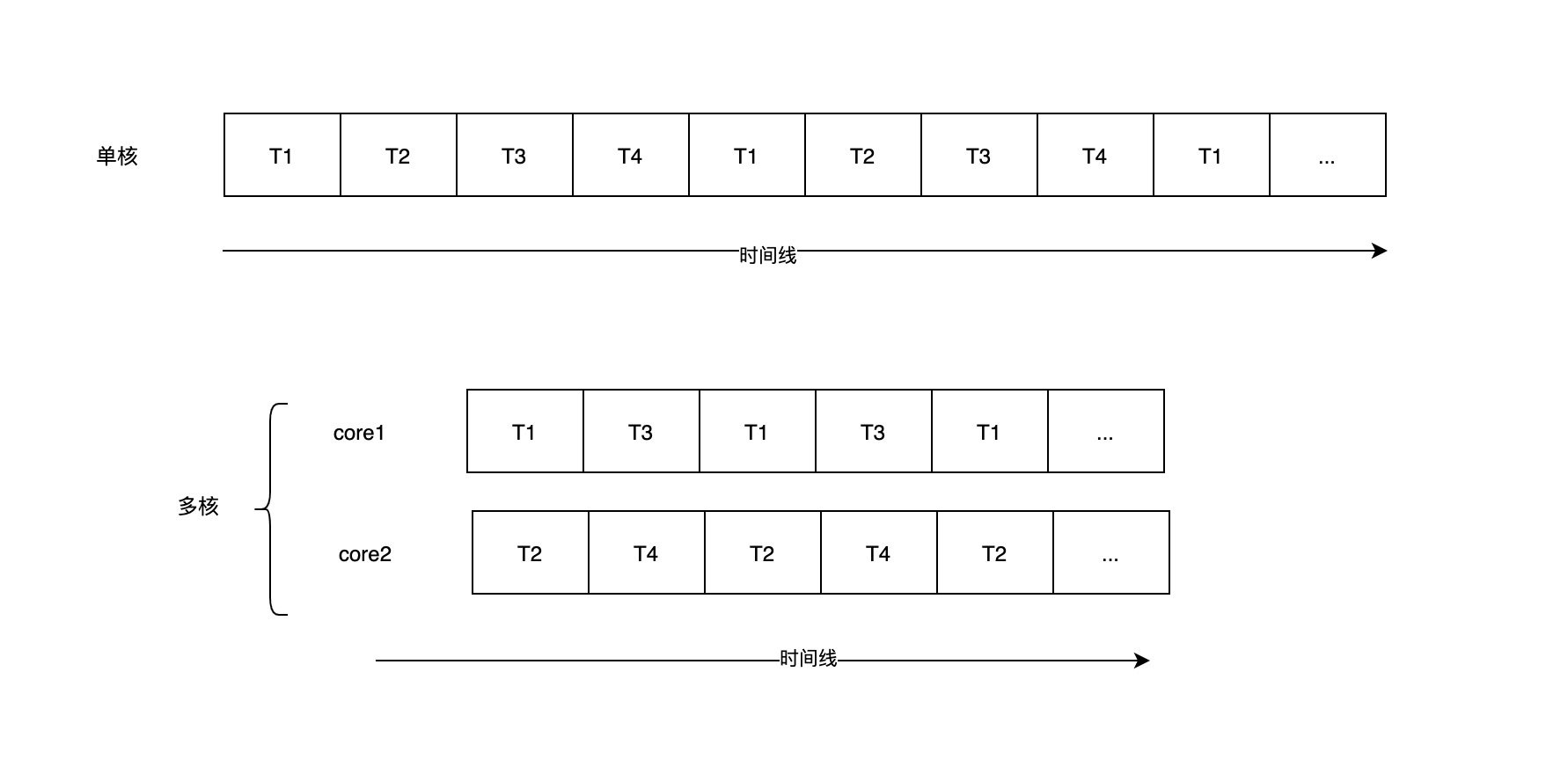
虽然多核处理器可以保证并行的计算,但是,实际中程序的数量以及实际运行的线程数量会比 CPU 核心数多得多。因此,为了平衡每个线程能够被 CPU 处理的时间以及最大化利用 CPU 资源,操作系统需要在适当的时间,通过定时器中断(Timer interrupt)、I/O 设备中断、操作系统调用来执行上下文切换(context switch)。
当发生线程上下文切换时,需要首先从操作系统用户态(user mode)转移到内核态(kernel mode),记录上一个线程(P1)的重要寄存器值(例如栈指针)、进程状态等信息,这些信息存储在操作系统线程控制块(Thread control block)当中。
切换到下一个要执行的线程时,需要加载重要的 CPU 寄存器值,并从内核态转移到操作系统用户态。如果线程在上下文切换时,属于不同的进程,就需要更新额外的状态信息,以及内存地址空间,将新的页表(page tables)导入内存。
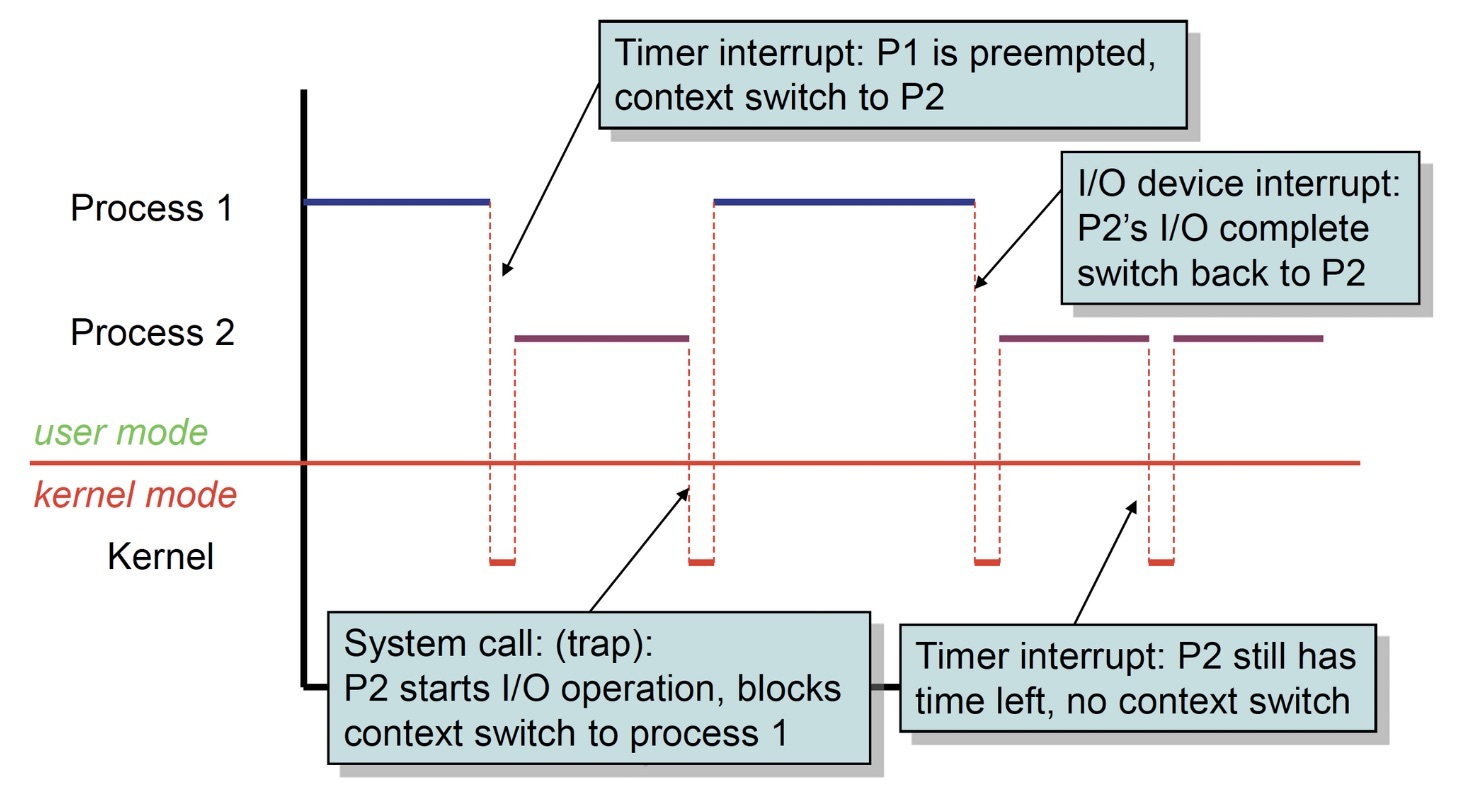
如果线程的上下文切换发生在不同的进程之间,情况会更加复杂。因为进程内存地址空间的切换会导致缓存失效。所以不同进程的切换要显著慢于同一进程中线程的切换。但是,现代的 CPU 也使用了快速上下文切换(rapid context switch)技术,来解决不同进程切换带来的缓存失效问题。
协程与线程的区别
明白了操作系统最基本的线程以及线程与进程的区别,接下来我们继续了解线程和协程到底有什么不同。
在 Go 语言中,协程被认为是轻量级的线程。但是和线程不同的是,操作系统内核感知不到协程的存在。协程的管理,依赖 Go 语言运行时自身提供的调度器(scheduler)。同时,Go 中的协程是从属于某一个线程的,协程与线程是多对多的关系。Go 调度器可以将多个协程分配到一个线程中,一个协程也可能会转移到多个线程中执行。
你可能会问,为什么 Go 语言需要在线程的基础上抽象出协程的概念,难道直接使用线程不香吗?
要回答这个问题,我们就需要去深入地理解线程与协程的区别。下面我从上下文切换的速度、调度策略、栈的大小这三个方面,来给你分析线程与协程的不同之处。
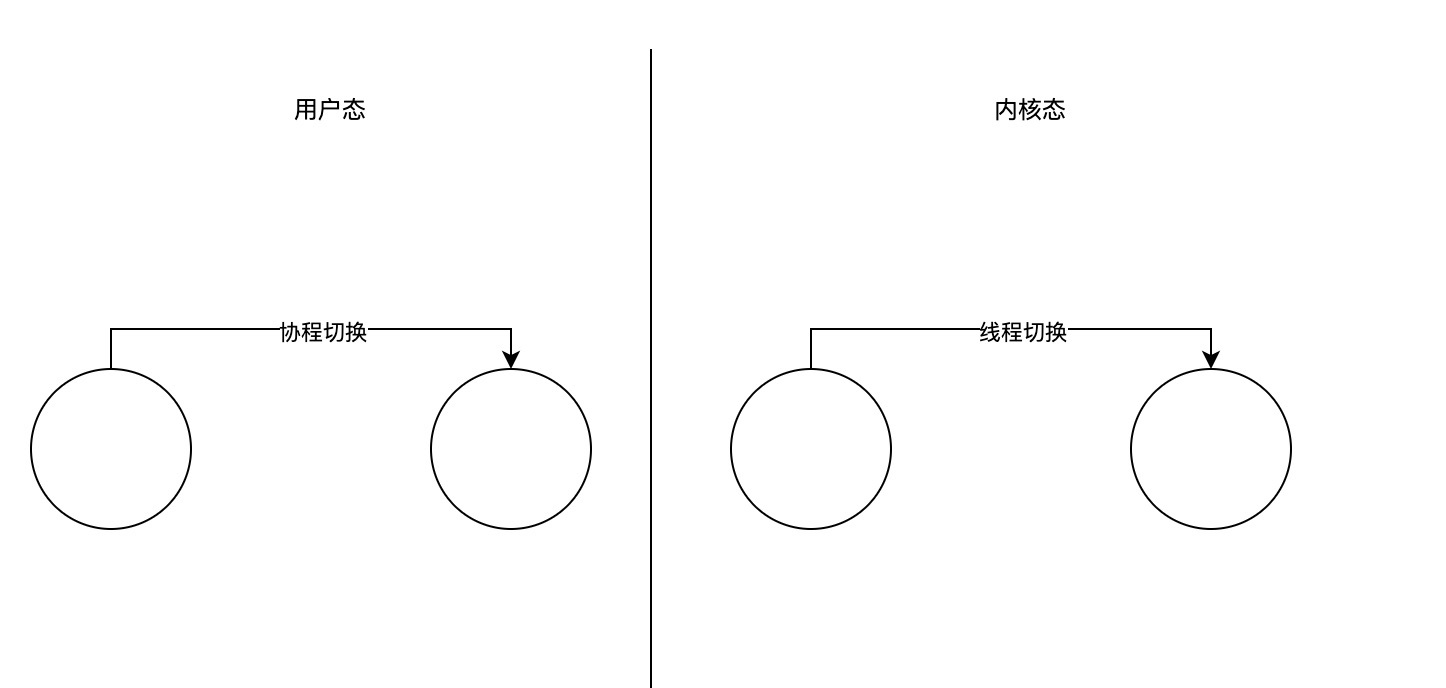
首先,对于上下文切换的速度,协程要快于线程,因为协程的切换不用经过操作系统用户态与内核态的切换,并且 Go 语言中协程的切换只需要保留极少的状态和寄存器变量值(SP/BP/PC),而线程的切换会保留额外的寄存器变量值(例如浮点寄存器)。在 Go 语言中,上下文切换速度的一个可参考量化指标是,线程大约为 1~2 微秒,协程大约是 0.2 微秒,比线程快数倍。
其次,在调度策略方面,线程的调度基本上是抢占式的,操作系统调度器为了均衡每一个线程的执行周期,会定时发出中断信号强制执行线程上下文切换。而协程一般情况下是协作式调度的。当一个协程处理完自己的任务后,可以主动将执行权限让给其他协程。这意味着协程能更好地在规定时间内完成自己的工作,而不会被任意抢占。当一个协作式运行的时间过长,Go 语言调度器才会强制抢占其执行。
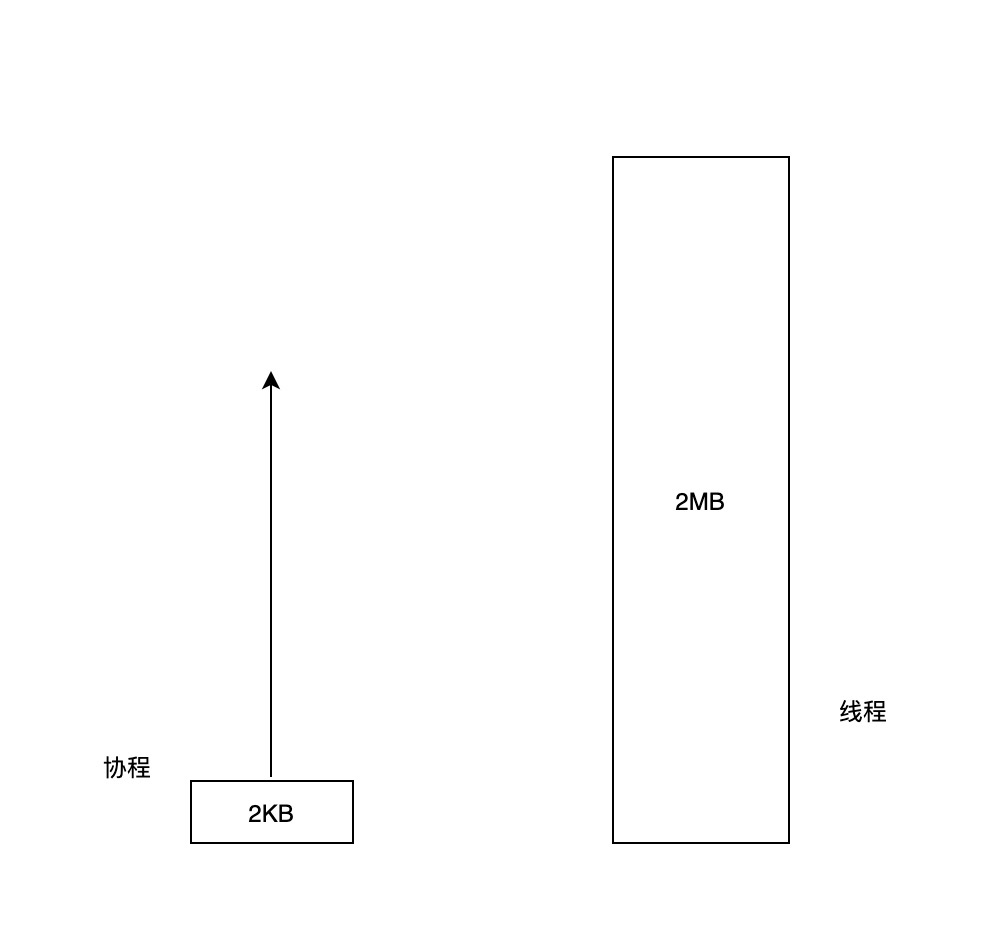
最后是栈的大小方面。线程的栈大小一般是在创建时指定,为了避免出现栈溢出(Stack Overflow)的错误,默认的栈大小会相对较大(例如 2M),这意味着创建 1000 个线程就需要消耗 2G 的虚拟内存,这大大限制了线程创建的数量(虽然今天 64 位的虚拟内存地址空间已经让这种限制变得不太严重)。而 Go 语言中的协程栈默认为 2KB,在实践中,我们经常会看成千上万的协程存在。另外,线程的栈在运行时不能够更改,而协程栈在 Go 运行时的帮助下可以动态检测栈的大小,进行扩容和收缩。由于协程栈很小,在实践中,协程常被看作是一种轻量级的资源。
Go 语言中经典的 GMP 的概念模型其实生动概括了线程与协程的关系:它表明了 Go 进程中的众多协程其实依托于线程,借助操作系统将线程调度到 CPU 执行从而最终完成对于协程的执行。
在 GMP 模型中,G 代表的是 Go 中的协程(Goroutine),M 代表的是实际的线程,而 P 代表的是 Go 逻辑处理器(Process),Go 语言抽象出了逻辑处理器 P,为了方便协程调度与缓存。
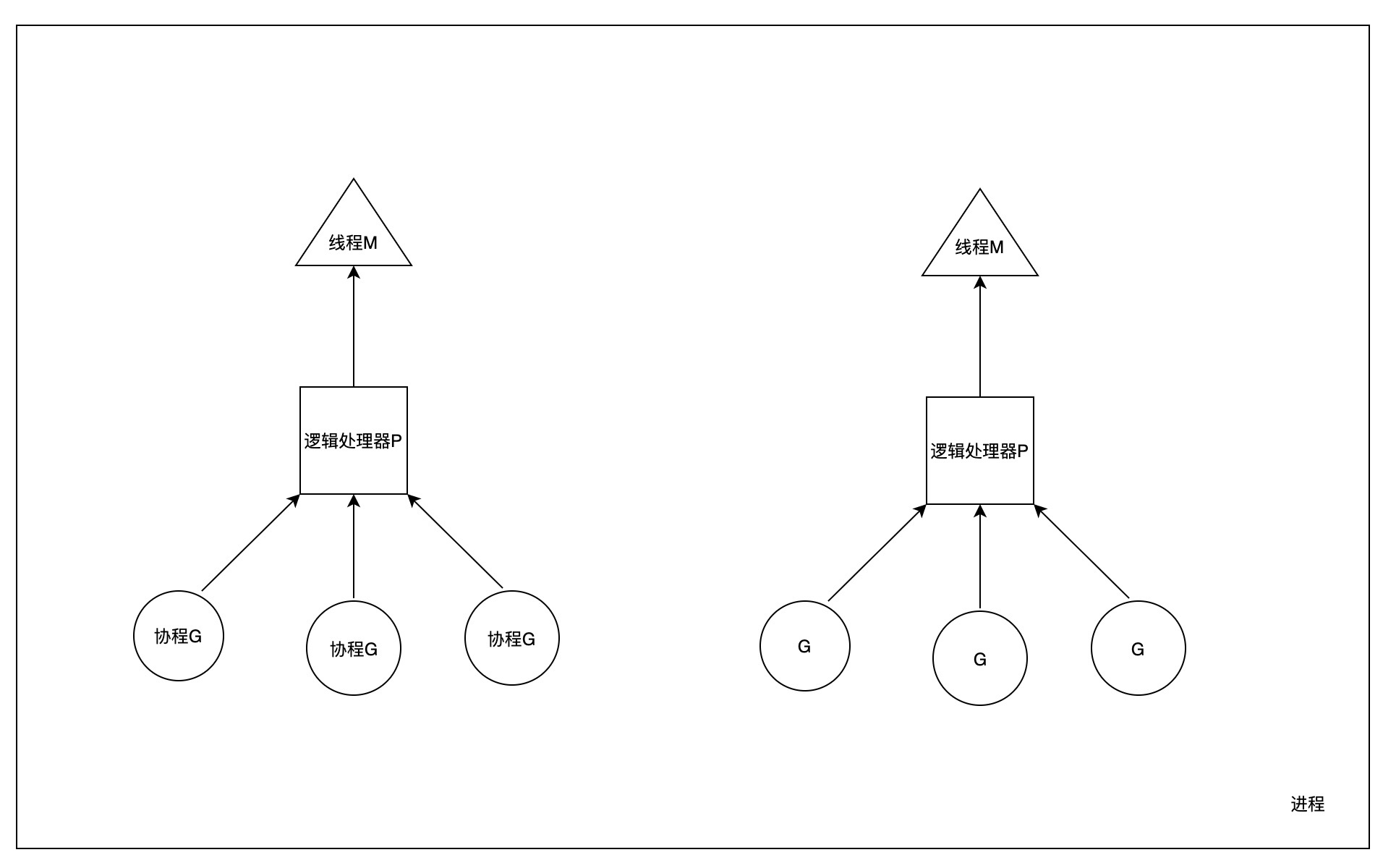
在任一时刻,一个 P 中可能包含了多个协程 G,同时一个 P 在任一时刻与唯一的线程 M 绑定。就是说协程与 P 的关系是多对多的,而 P 与线程的关系是一对一的,最终完成了一个线程与多个协程的绑定。但是这种绑定是动态的,借助于 Go 运行时调度器,一个协程可能会被多次调度,并调度到不同的线程中执行。所以,Go 的协程本质上是依赖于线程执行的,但是由于协程在用户态的上下文切换以及动态扩容的栈内存,导致在 Go 语言中可以轻易地创建成千上万个协程。
在后面的视频中,我还会给你介绍到协程是怎么通过 Go 语言运行时的调度器,公平调度到不同线程中的,有兴趣的话你可以关注一下。
总结好了,今天的分享就结束了。对于线程与进程、协程的关系,你可以这么理解:协程的运行依托于操作系统对于线程的调度执行,而线程的执行离不开操作系统对于进程的管理。
我是郑建勋,希望我的分享可以帮助到你,也希望你在视频下方的留言区和我一起讨论。